
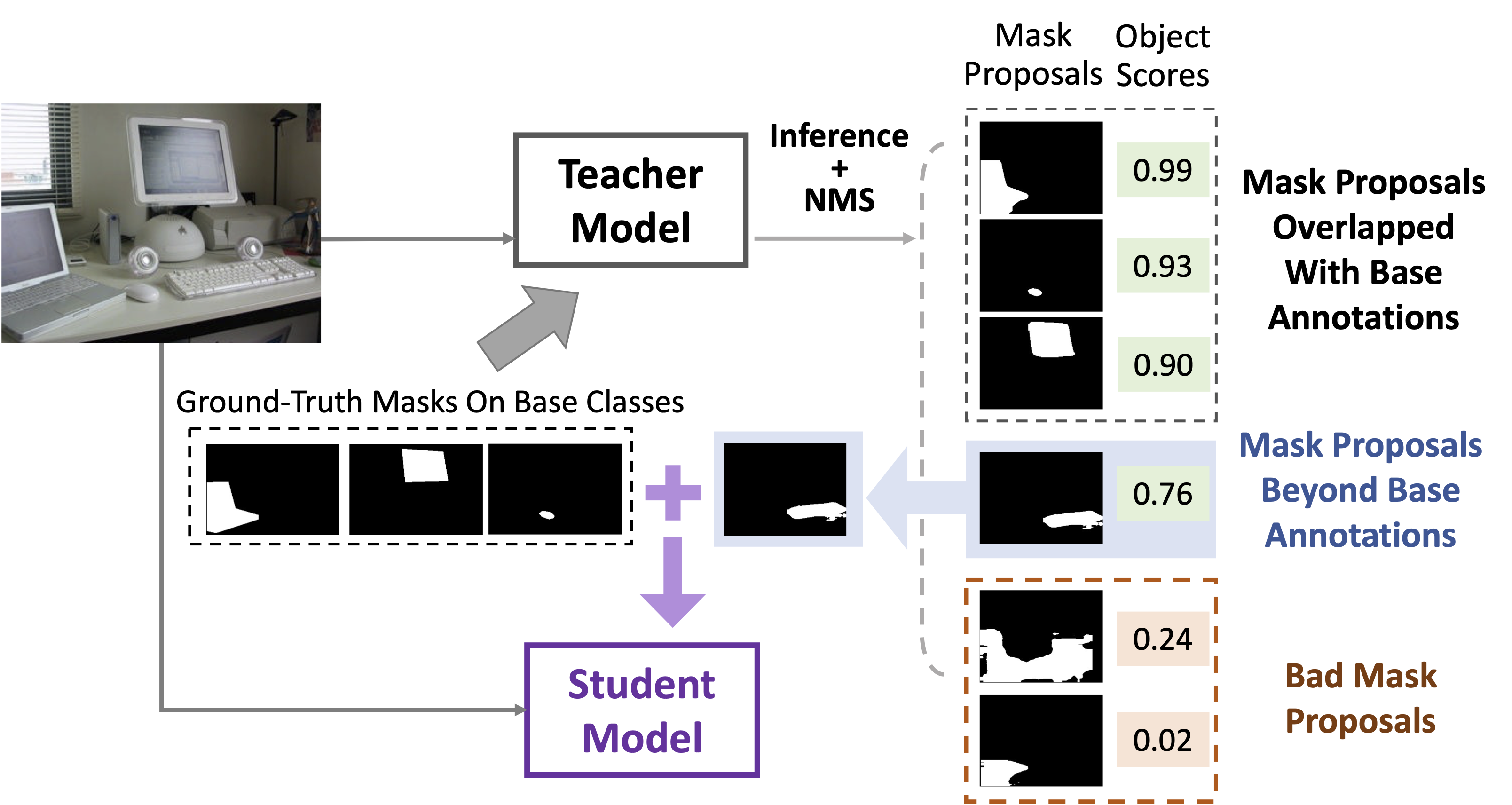
Progressive Distillation
We present a new method for open-vocabulary universal image segmentation, which is capable of performing instance, semantic, and panoptic segmentation under a unified framework. Our approach, called MasQCLIP, seamlessly integrates with a pre-trained CLIP model by utilizing its dense features, thereby circumventing the need for extensive parameter training.
MasQCLIP emphasizes two new aspects when building an image segmentation method with a CLIP model: (1) a student-teacher module to deal with masks of the novel (unseen) classes by distilling information from the base (seen) classes; (2) a fine-tuning process to update model parameters for the queries \(Q\) within the CLIP model. Thanks to these two simple and intuitive designs, MasQCLIP is able to achieve state-of-the-art performances with a substantial gain over the competing methods by a large margin across all three tasks, including open-vocabulary instance, semantic, and panoptic segmentation.
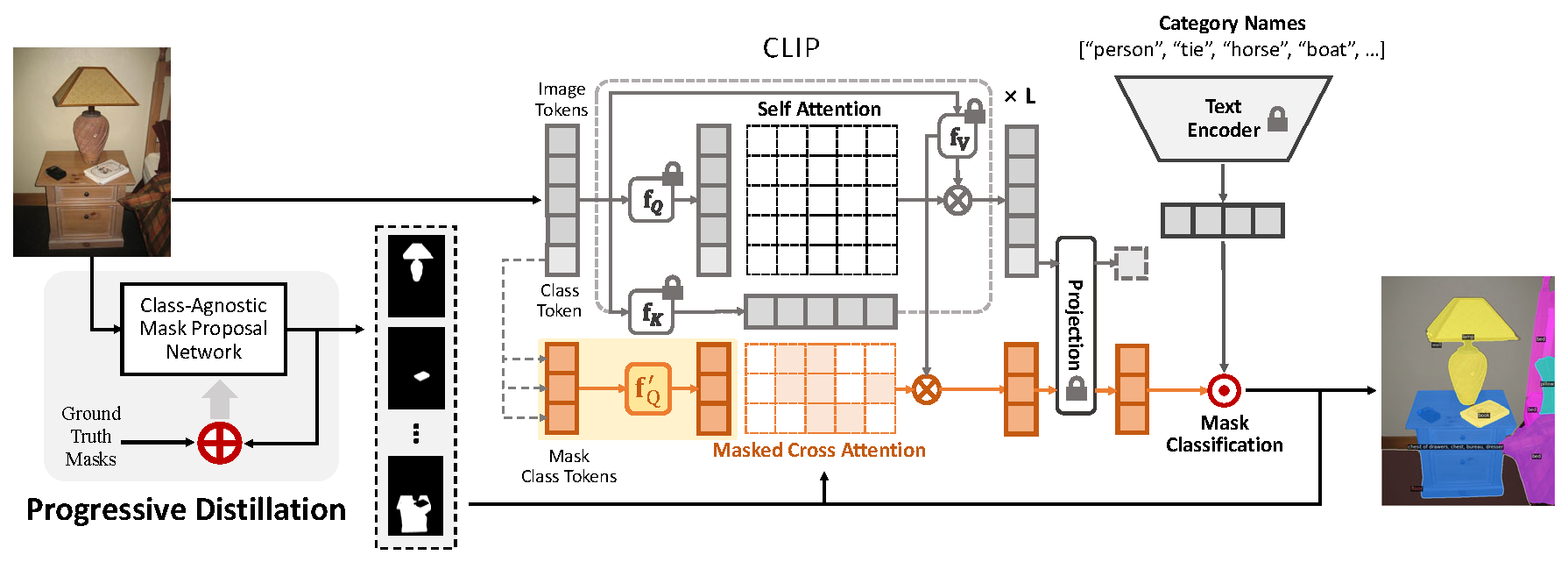
To enhance adaptation from image classification to mask classification while maintaining the generalization ability of CLIP, we apply new query projections \(f_Q^\prime\) to each cross-attention layer for Mask Class Tokens, i.e.
$$\text{CrossAttn}(\cdot) = \text{softmax}(\mathbf{Q}_{\text{mask}}^\prime K_{\text{img}}^T + \mathcal{M}_{\text{mask}}) \cdot V_{\text{img}}$$
$$\mathbf{Q}_{\text{mask}}^\prime, K_{\text{img}}, V_{\text{img}} = \mathbf{f_Q^\prime}(x_\text{mask}), f_K(x_\text{img}), f_V(x_\text{img})$$
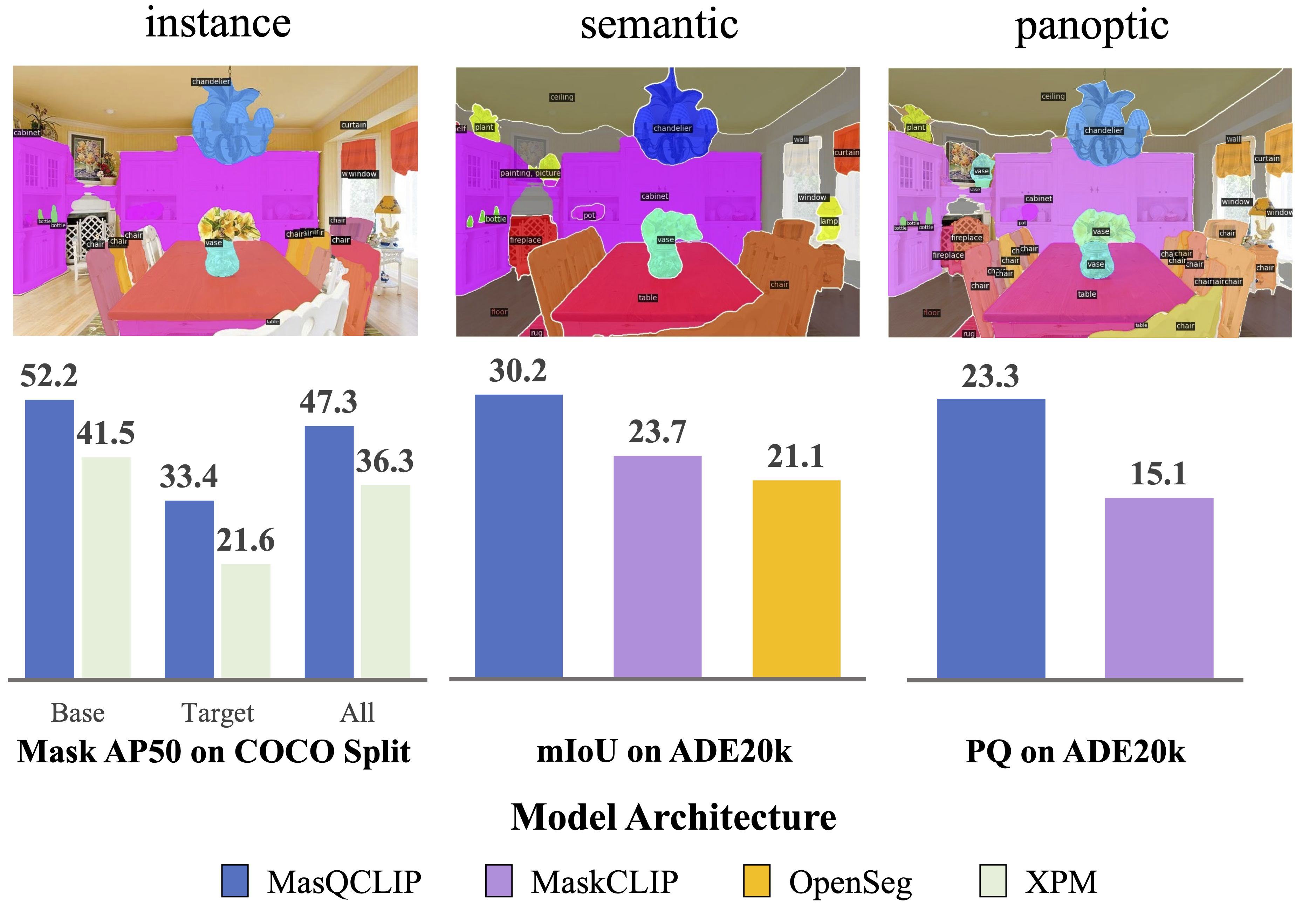
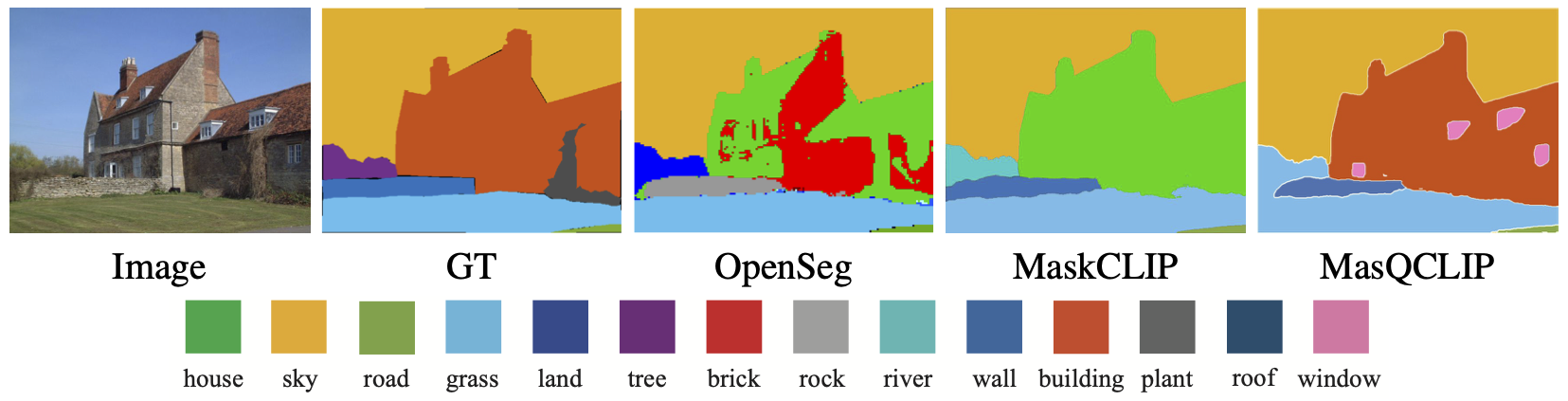
Semantic Segmentation
Instance Segmentation

Panoptic Segmentation

@inproceedings{xu2023masqclip,
author = {Xu, Xin and Xiong, Tianyi and Ding, Zheng and Tu, Zhuowen},
title = {MasQCLIP for Open-Vocabulary Universal Image Segmentation},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {887-898}
}